# TCP
:传输控制协议(Transmission Control Protocol)
- 属于传输层协议,用于让一个主机向另一个主机传输网络数据包。
- 特点:
- 全双工通信。
- 面向连接:通信双方在通信之前要先建立连接,作为信道。
- 这里的连接是指逻辑网络上的连接,不是建立物理信道。
- 传输可靠:可实现顺序控制、差错控制、流量控制、拥塞控制。
# 架构
TCP 协议采用 C/S 架构:
- server
- :称为服务器、被动连接方,由一个主机担任。需要持续监听某个 TCP 端口,供 client 连接。
- Linux 系统通常可监听的端口号范围为 0~65535 ,例如 HTTP 服务器通常监听 TCP 80 端口。
- client
- :称为客户端、主动连接方,由任意个主机担任,可以连接到 server 。
- server
例:假设 client 想与某个 server 按 TCP 协议进行通信(比如传输一张图片),则一般流程如下:
- client 事先知道 server 的 IP 地址、监听的端口号。
- 建立连接:client 发送几个特殊的 TCP 包给 server ,请求用 client 的随机一个端口,连接到 server 的指定一个端口。
- 正式通信:双方端口组成一个全双工信道,可以发送任意个包含任意 payload 的 TCP 包。
在类 Unix 系统中进行 TCP/UDP 通信时,通信双方需要各创建一个 Socket 文件,以读写文件的方式进行通信。
- 比如 client 向本机的 Socket 文件写入数据,会被自动传输到 server 端的 Socket 文件,被 server 读取到数据。
# 数据格式
UDP 协议传输 payload 数据时,会封装成至少一个数据包,每个数据包称为段(segment),其数据结构如下:
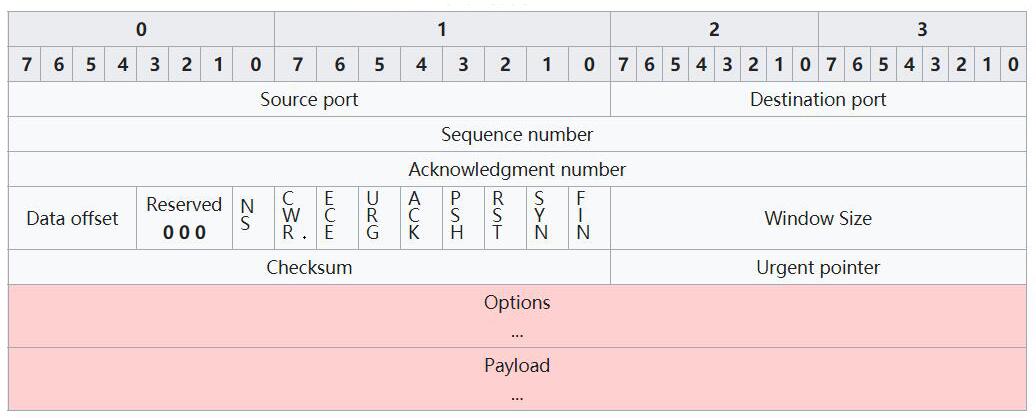
- Source Port :源端口,占 16 bits 空间。
- Dest Port :目标端口,占 16 bits 。
- Seq number :序列号,占 32 bits 。
- Ack number :确认号,占 32 bits 。
- Data offset :偏移量,占 4 bits 。表示 payload 的起始坐标,即 TCP headers 的总长度。
- Reserved :保留给未来使用,占 3 bits ,默认值为 0 。
- Flag :标志符,占 9 bits 。每个 bit 代表一个标志位,默认值为 0 。
- NS
- CWR
- ECE
- URG=1 :表示该 TCP 包是紧急数据,应该被优先处理。
- ACK=1 :表示确认。注意它与 Ack number 是不同字段。
- PSH=1 :表示该 TCP 包应该被发送方立即发送、被接收方立即上报。
- 例如 Linux 在 TCP 通信时设计了发送缓冲区、接收缓冲区,可暂存一些 bytes 数据。
- 发送 TCP 包时,默认会等发送缓冲区堆积了较多数据时,才下发到网络层。
- 接收 TCP 包时,默认会等接收缓冲区堆积了较多数据时,才上报到应用层。
- 使用缓冲区,能提高通信效率,但增加了通信延迟。
- 假设缓冲区已有一些 bytes 数据,此时新增一个数据包的 payload :
- 如果该数据包设置了 URG=1 ,则会立即处理该包的 payload ,跳过处理缓冲区已有的数据。
- 如果该数据包设置了 PSH=1 ,则会立即处理该包的 pyaload ,以及缓冲区已有的全部数据。
- 例如一个应用层的 HTTP 报文可能拆分成多个 TCP 包发送,最后一个 TCP 包设置了 PSH=1 。
- 例如 Linux 在 TCP 通信时设计了发送缓冲区、接收缓冲区,可暂存一些 bytes 数据。
- RST=1 :表示拒绝 TCP 连接,不愿意接收对方发送的数据包。
- SYN=1 :表示请求建立 TCP 连接。
- FIN=1 :表示请求关闭 TCP 连接,但依然愿意接收对方发送的数据包,直到正式关闭连接。
- Window size :表示本机接收窗口的大小,占 16 bits 。
- Checksum :校验和,占 16 bits 。
- 计算方法:
- 将 TCP headers 中的 Checksum 清零。
- 在 TCP headers 之前加上 12 bytes 的伪头部,包含几个字段:Source IP、Dest IP、1 个 保留字节、protocol(传输层协议号)、length(原 headers + payload 的长度)。
- 计算整个 TCP 数据包(包括伪头部、原 headers、payload)的 Checksum ,记录到 TCP headers 中。
- 计算方法:
- Urgent pointer
- Options :在 TCP headers 的末尾可添加一些额外的配置参数,实现扩展功能。例如:
- MSS(Maximum Segment Size):允许传输的 TCP 包的最大体积。
- 以太网中,通常限制 IP 包的最大体积 MTU 为 1500 Bytes 。
- TCP 包需要封装成 IP 包之后才能传输。而封装时,需要添加几十字节的 IP 协议的 metadata ,增加了网络流量。为了节约网络流量,应该让每个 TCP 包只封装成一个 IP 包(而不是多个),因此通常限制每个 TCP 包的最大体积 MSS 为 1460 bytes 。
- 如果一个 TCP 包超过 MSS ,则会被丢弃,不会传输。
- TCP 三次握手时,通信双方可通过 SYN 包协商 MSS、Window scale、SACK-permitted 的值,然后作用于本次 TCP 通信的所有数据包。
- Window scale :用于放大 Window size 。
- SACK :用于选择性确认。
- SACK-permitted :表示本机启用了 SACK 功能。
- Timestamps :时间戳,占 32 bits 。
- 该时间戳不表示 Unix 时间,而是通常每隔几十 ms 就递增 1 。
- 常用于计算 TCP 包的传输耗时、 RTT ,防止序号回绕。
- Nop :表示 No-Operation ,用作各个 Options 之间的分隔符。
- MSS(Maximum Segment Size):允许传输的 TCP 包的最大体积。
- Payload :该数据包负责传输的数据,取值可以为空。
- payload 之前的数据都只是用于描述 TCP 数据包的元数据,称为 TCP 头部(headers)。
# 建立连接
建立 TCP 连接时需要经过三个步骤,称为 "三次握手" :
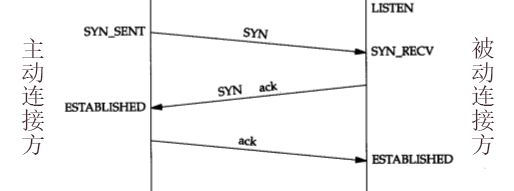
- client 发送一个 SYN=1 的 TCP 包给 server ,表示请求连接到 server 的指定一个 TCP 端口。
- client 发送 SYN 包之后,如果超过一定时间未收到 server 的回复,则认为丢包了,于是重传 SYN 包。
- server 收到后,回复一个 ACK=1、SYN=1 的 TCP 包,表示接受对方的连接,而且自己也请求连接。
- 如果 client 收到该包,就证明自己发送的包能被对方接收,而对方发送的包也能被自己接收。因此从 client 的角度来看,判断双方能相互通信。
- server 发送 SYN+ACK 包之后,如果超过一定时间未收到 client 的回复,则认为丢包了,于是重传 SYN+ACK 包。
- client 收到后,发送一个 ACK=1 的 TCP 包,表示接受对方的连接,从而正式建立连接。
- 如果 server 收到该包,则从 server 的角度来看,判断双方能相互通信。
- 如果 server 未收到该包(比如丢包了),则 server 处于 SYN_RECV 状态,client 处于 ESTABLISHED 状态。
- 正常情况下,client 发出 ACK 包之后,通常认为已成功建立 TCP 连接,会开始发送携带正式 payload 的 TCP 包。而正式通信的 TCP 包总是包含 ACK=1 ,因此也会使得 server 进入 ESTABLISHED 状态。
- 恶意情况下,client 可能一直不发出 ACK 包,使得 server 长时间处于 SYN_RECV 状态。如果有大量这样未完成的 TCP 连接,则会占用 server 的大量资源,造成 SYN FLOOD 攻击。
- client 发送一个 SYN=1 的 TCP 包给 server ,表示请求连接到 server 的指定一个 TCP 端口。
建立 TCP 连接时的 Socket 状态变化:
LISTEN:server 正在监听该 Socket ,允许接收 TCP 包。SYN_SENT:client 已发出 SYN=1 的 TCP 包,还没有收到 SYN+ACK 包。SYN_RECV:server 已收到 SYN 包,还没有收到 ACK 包。ESTABLISHED:已建立连接。
三次握手的总耗时大概为 1.5 倍 RTT 。不过在第三步,client 发出 ACK 包之后,通常立即进入 ESTABLISHED 状态。从 client 的角度来看,建立 TCP 连接的耗时大概为 1 倍 RTT 。
# 关闭连接
关闭 TCP 连接时需要经过四个步骤,称为 "四次分手" :
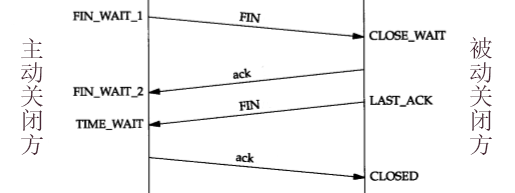
- 主动关闭方发送一个 FIN=1 的 TCP 包,表示请求关闭连接。
- 被动关闭方收到后,先回复一个 ACK 包,表示同意关闭连接。等自己准备好之后也发送一个 FIN 包,表示请求关闭连接。
- 主动关闭方收到后,发送一个 ACK 包,表示自己已关闭连接。
- 被动关闭方收到后,正式关闭连接。
只有 client 能主动建立连接,但 client、server 都可以主动关闭连接。
- 建立连接时,通信双方都要发送一个 SYN 包、一个 ACK 包。
- 关闭连接时,通信双方都要发送一个 FIN 包、一个 ACK 包。
关闭 TCP 连接时的 Socket 状态变化:
FIN-WAIT-1FIN-WAIT-2TIME-WAIT- 主动关闭方在第 3 步之后,已关闭 TCP 连接,而 Socket 处于 TIME-WAIT 状态,还要等待 2*MSL 时间才能变成 CLOSED 状态,从而避免对方来不及关闭 TCP 连接。
- MSL(Maximum Segment Lifetime):TCP 段在网络传输中的最大生存时间,超过该时长则会被丢弃。
- RFC 793 定义的 MSL 为 2 分钟,而 Linux 中 MSL 通常为 30 秒。
- 如果一个 server 被大量 client 建立 TCP 连接,则建议 server 不要主动关闭 TCP 连接,避免产生大量 TIME-WAIT 状态的 Socket ,浪费内存。这样有两种结果:
- client 主动关闭连接,则 server 可立即关闭 Socket ,而 client 要保留 TIME-WAIT 状态的 Socket 一段时间。
- client 不主动关闭连接,则 server 可等 TCP 连接长时间空闲、未用于传输数据,才主动关闭它。
CLOSE-WAIT- 在第 2 步,如果被动关闭方没有立即调用 close() 关闭端口,则会长时间处于 CLOSE-WAIT 状态。
LAST-ACKCLOSED:TCP、Socket 都已关闭。
# 数据传输
- 建立 TCP 连接之后,通信双方就可以开始传输包含自定义 payload 的 TCP 包。
- 建立 TCP 连接之后,一般会将 TCP 连接保持一段时间,供双方多次收发数据,称为 keepalive 。等双方不再使用时,才关闭 TCP 连接。
- 一般程序进行 TCP 通信时,不需要自己实现 TCP 协议的具体逻辑,只需调用操作系统的 API ,操作系统会自动完成三次握手、顺序控制、差错控制等任务。
- 例:假设两个程序 A、B 分别位于两个 Linux 主机上,已建立 TCP 连接,可调用 send()、recv() 函数来发送、接收数据。流程如下:
- 程序 A 调用 send() ,请求操作系统发送一批 bytes 数据。
- 程序 A 的操作系统先将 bytes 数据暂存到发送缓冲区,然后取出这些数据作为 payload ,自动封装为一个或多个 TCP 包,最后发送。
- 程序 B 的操作系统收到一个或多个 TCP 包,自动解包,将其中的 payload 暂存到接收缓冲区。
- 程序 B 调用 recv() ,请求接收数据。此时,操作系统会取出接收缓冲区中的 bytes 数据。
- 例:假设两个程序 A、B 分别位于两个 Linux 主机上,已建立 TCP 连接,可调用 send()、recv() 函数来发送、接收数据。流程如下:
# 顺序控制
TCP 通信时,双方会分别记录 Seq number、Ack number 两个序列号。
- 如果本机通过 TCP payload 发送了 n bytes 的数据,则将本机记录的 Seq number 增加 n 。
- 如果本机通过 TCP payload 接收了 n bytes 的数据,则将本机记录的 Ack number 增加 n 。
- 刚建立 TCP 连接时,双方会分别随机生成一个 Seq number 的初始值,称为 ISN(Initial Sequence Number)。而本机的 Ack number 的初始值取决于对方的 ISN 。
- 优点:利用序列号,发送方可同时发送多个 TCP 包(只要不超过发送窗口),不必控制发送顺序,反正接收方能根据序列号对这些 TCP 包排序。
例:主机 A 向主机 B 发送一个 HTTP 请求,并收到一个 HTTP 响应,其下层的 TCP 通信过程如下
- 首先 TCP 三次握手:
- 主机 A 发送一个 SYN=1 的 TCP 包,表示请求连接。其中:
- Seq number = 1000 ,假设这是主机 A 的 ISN 。
- Ack number = 0 ,因为还没收到过数据。
- payload 长度为 0 。
- 主机 B 回复一个 ACK=1、SYN=1 的 TCP 包,表示接受连接。其中:
- Seq number = 2000 ,假设这是主机 B 的 ISN 。
- Ack number = 1001 ,表示收到了主机 A 的 Seq number ,预计接收的下一个字节的序列号。
- payload 长度为 0 。
- 主机 A 发送一个 ACK=1 的 TCP 包,正式建立连接。其中:
- Seq number = 1001 。TCP 握手阶段有点特殊,虽然没有发送 payload ,但双方发出 ACK=1 包时,都会将 Seq number 增加 1 。
- Ack number = 2001 ,表示收到了主机 B 的 Seq number ,预计接收的下一个字节的序列号。
- payload 长度为 0 。
- 主机 A 发送一个 SYN=1 的 TCP 包,表示请求连接。其中:
- 然后发送 HTTP 请求:
- 主机 A 发送一个 ACK=1 的 TCP 包,包含 400 bytes 的 HTTP 请求报文。其中:
- Seq number = 1001 ,与上一步相同。
- Ack number = 2001 ,与上一步相同。
- payload 长度为 400 bytes 。发送之后,会将本机的 Seq number 增加到 1401 。
- 主机 B 回复一个 ACK=1 的 TCP 包。其中:
- Seq number = 2001 。
- Ack number = 1401 ,增加了 400 。
- payload 长度为 0 。
- 主机 A 发送一个 ACK=1 的 TCP 包,包含 400 bytes 的 HTTP 请求报文。其中:
- 最后收到 HTTP 响应:
- 主机 B 发送一个 ACK=1 的 TCP 包,包含 500 bytes 的 HTTP 响应报文。其中:
- Seq number = 2001 ,与上一步相同。
- Ack number = 1401 ,与上一步相同。
- payload 长度为 500 bytes 。发送之后,会将本机的 Seq number 增加到 2501 。
- 主机 A 回复一个 ACK=1 的 TCP 包。其中:
- Seq number = 1401 。
- Ack number = 2501 ,增加了 500 。
- payload 长度为 0 。
- 主机 B 发送一个 ACK=1 的 TCP 包,包含 500 bytes 的 HTTP 响应报文。其中:
- 首先 TCP 三次握手:
防止序号回绕(Protection Against Wrapped Sequences,PAWS)
- :TCP headers 中用 32 bits 空间记录序列号,如果序列号的取值达到最大值,则从 0 开始重新递增,称为回绕。此时接收窗口中同时存在新旧 TCP 包,需要判断它们的先后顺序。
- 通常每传输 4 GB 数据,序列号就回绕一次。
- 常见的解决方案是,比较两个 TCP 包 headers 中的 timestamp ,从而判断它们的先后顺序。不过极低的概率下,timestamp 与序列号会同时发生回绕。
TCP 会话劫持(TCP Session Hijack)
- :一种网络攻击方式。假设主机 A 与主机 B 已建立 TCP 连接,攻击者可以运行主机 C ,窃听到当前的 Seq number、Ack number ,从而冒充主机 A 与主机 B 通信。
- 同时,攻击者对真正的主机 A 进行 DoS 攻击,使它不能与主机 B 通信。
- 如果攻击者担任主机 A 与主机 B 的通信中间人,比如路由器,则更容易冒充主机 A 。
- 对策:
- 随机生成 ISN ,减少被预测的概率。不过依然难以避免被窃听。
- 启用 SSL 协议,加密 TCP 包中的 payload 。
- 启用 IPsec 协议,加密 IP 包中的 payload ,即 TCP segment 。
- :一种网络攻击方式。假设主机 A 与主机 B 已建立 TCP 连接,攻击者可以运行主机 C ,窃听到当前的 Seq number、Ack number ,从而冒充主机 A 与主机 B 通信。
# 差错控制
确认
- :发送方每发送一个 TCP 包,都要根据序列号确认它是否传输成功。
- 例:
- 假设通过 TCP 协议传输 300 bytes 的数据,发送方可以发送 3 个 TCP 包,分别携带 100 bytes 的 payload ,分别在 TCP headers 中声明 Seq number = 0 、Seq number = 100 、Seq number = 200 ,表示 payload 中第一个字节的序列号。
- 接收方每收到一个 TCP 包,就回复一个 TCP 包,其中 payload 为空,并在 TCP headers 中声明 Ack number ,取值等于 Seq number + payload length ,表示预计接收的下一个字节的序列号。
- 接收方收到 ACK 包,则确认序列号小于 Ack number 的数据传输成功。
累计确认
- :发送方不必按顺序接收 ACK 包,只要收到一个 ACK 包,则认为小于当前 Ack number 的数据全部传输成功。
- 例:假设发送方发送 3 个 TCP 包,分别携带 100 bytes 的 payload ,Seq number 分别为 0、100、200 。而接收方回复 3 个 ACK 包,Ack number 分别为 100、200、300 。
- 如果 3 个 ACK 包在传输时全部丢失,则发送方会触发超时重传。
- 如果第 1、2 个 ACK 包丢失,但第 3 个 ACK 包传输成功,则发送方得知当前的 Ack number = 300 ,说明之前的 TCP 包全部传输成功,不必重传。
校验和
- :接收方每接收一个 TCP 包,都要计算一次 Checksum ,检查它是否与 TCP 包原有的 Checksum 相同,从而确保 TCP 包在网络传输过程中没有变化。
- 如果一个 TCP 包不通过校验,或序列号重复,则接收方会丢弃该 TCP 包,导致发送方触发超时重传。
# 重传
正常情况下,发送方发出的一个数据包,会经过路由器、交换机等通信设备转发,最终到达接收方。
- 异常情况下,数据包可能没有到达接收方,或者到达了但内容变化。此时认为数据包传输失败、出错。
- TCP 协议要求发送方,检查自己发送的每个包是否传输成功。如果传输失败,则重新发送该包,该机制称为重传(Retransmission)。
- 相比之下,IP、UDP 协议只管发送数据包,不检查是否发送成功。
- TCP 协议中,仅由发送方决定是否重传。路由器、交换机等中间环节不会检查数据包是否传输成功,接收方也不会。
- 什么时候触发重传?通常是超时重传、快速重传。
- 重传哪些 TCP 包?通常是根据 SACK 判断。
超时重传
- :如果发送方发送一个 TCP 包之后,超过 RTO(Retransmission Timeout,重传超时) 时长未收到对应的 ACK 包,则重新发送该 TCP 包。
- 超时的常见原因:
- 通信延迟突然变大
- 发送的 TCP 包丢失
- 回复的 ACK 包丢失
- RTT(Round Trip Time,往返时间):一个主机与另一个主机通信时,从发出消息到收到回复的耗时,是端到端延迟的两倍。
- 发送方设置的 RTO ,应该略大于 RTT 。
- 如果 RTO 比 RTT 大很多,则 TCP 包丢失时,要等更久时间才重发。
- 如果 RTO 比 RTT 小很多,则 TCP 包没有丢失时,也容易重发,加剧网络拥塞。
- 例如 Linux 会根据网络最近一段时间的 RTT 平均值,动态设置 RTO 。每触发一次超时重传,就会将 RTO 翻倍,然后继续统计 RTT 。
快速重传(Fast retransmit)
- :如果发送方重复收到 3 个 Ack number = N 的包,则认为 Seq number = N 的包传输失败,不等超时就立即重传。
- 例:假设发送方发送 5 个 TCP 包,分别携带 100 bytes 的 payload ,Seq number 分别为 0、100、200、300、400 ,其中第二个包传输失败。则流程如下:
- 接收方收到 Seq number = 0 的包,于是回复一个 Ack number = 100 的包。
- 接收方未收到 Seq number = 100 的包,却收到 Seq number = 200 的包,发现它的序列号不符合 Ack number 预期,因此不接受该包,并回复一个 Ack number = 100 的包。
- 接收方收到 Seq number = 300 和 Seq number = 400 的包,同理,分别回复一个 Ack number = 100 的包。
- 发送方重复收到 3 个 Ack number = 100 的包,于是判断第二个包大概率传输失败(小概率是传输乱序),立即从 Seq number = 100 处重新发送 payload 。
- 优点:与超时重传相比,快速重传能更快地发现传输失败的包,并重新发送。
- 缺点:快速重传时,发送方能判断某个 Seq number 的包传输失败,但不知道该包之后的各个包是否传输成功,因此需要重传在该 Seq number 之后的全部包,加剧网络拥塞。对此的解决方案是启用 SACK 功能。
- 如果接收方当前记录的 Ack number = N ,却收到 Seq number > N 的包,不符合 Ack number 预期。则不接受该包,但依然会将其 payload 暂存到接收缓冲区。因为:
- 如果 Seq number = N 的包传输失败,则发送方只需单独重传这个包,然后接收方就能得到完整的 payload 。
- 如果 Seq number = N 的包传输乱序,则很快会到达接收方,然后接收方就能得到完整的 payload 。
选择性确认(Selective Acknowledgements,SACK)
- :TCP 协议的一个可选功能。当通信双方都开启 SACK 功能时,接收方可在 TCP Options 中添加 SACK 参数,声明自己已收到哪些范围的数据,使得发送方可判断哪些数据传输失败,并重传这些数据。
- 例:假设发送方发送 5 个 TCP 包,分别携带 100 bytes 的 payload ,而接收方只收到第 0-99、200-499 bytes 的数据。
- 如果只是快速重传,则发送方会从 Seq number = 100 处重新发送,重传第 100-499 bytes 的数据,加剧网络拥塞。
- 如果开启 SACK 功能,则接收方会回复一个 Ack number = 100 的包,并在其中声明 SACK=200-499 ,使得发送方可判断接收方缺少第 100-199 bytes 的数据,并重传这些数据。
- 由于 TCP Options 整体最多占 40 bytes 空间,所以 SACK 参数最多包含 4 段范围,例如 SACK=0-99,200-499,600-699,800-899 。
重复确认(Duplicate SACK,D-SACK)
- :TCP 协议的一个可选功能,是基于 SACK 的扩展功能。允许接收方在 SACK 参数中声明的序列号小于当前的 Ack number ,表示重复收到该范围的数据。
- 例如接收方重复收到第 0-100 bytes 的数据,则回复一个 Ack number = 100 的包,并在其中声明 SACK=0-99 。
- 优点:通过 D-SACK ,发送方能发现 TCP 包被重复传输,有利于了解网络状态。
- 假设发送方触发一次超时重传,不能判断超时的原因。如果收到 D-SACK 包,就能判断发送的 TCP 包没有丢失。再结合 Ack number 的值,就能判断超时的原因是通信延迟突然变大,还是之前的 ACK 包丢失。
# 流量控制
什么是流量控制?
- 如果 TCP 采用串行通信模式,发送方每发送一个 TCP 包,等确认之后才能发送下一个 TCP 包,则发送 n 个 TCP 包需要等待 n 次 RTT ,传输数据的效率太低。
- 因此 TCP 协议支持并行通信,允许发送方同时发送多个 TCP 包,然后接收方回复多个 ACK 包,整体只需等待一次 RTT 。
- 优点:能大幅提高传输数据的效率,提高网速。
- 缺点:发送方发出的数据包,会先后经过多个通信节点(比如路由器)转发,最后到达接收方。如果并发传输的数据量过多,导致中间节点或接收方来不及处理,就会引发网络拥塞,甚至造成 DoS 攻击。
- 为了解决该问题,通常采用滑动窗口的机制,实现流量控制(Flow Control)。进一步地,还需要实现拥塞控制。
- 用户可测试从发送方到接收方的整条通信线路,每秒并发传输的最大数据量,记作最大带宽,单位为 mbps 。
接收窗口(receive window)
- :接收方的接收缓冲区的可用空间,单位 bytes 。
- 接收方可以同时接收多个 TCP 包,将 payload 暂存到接收缓冲区,等处理完了才删除接收缓冲区中的这些数据。
- 如果接收缓冲区的可用空间不足,则不能接收包含 payload 的新 TCP 包,只能丢包。
- TCP headers 中的 Window size 表示本机接收窗口的大小,占 16 bits 空间,因此接收窗口最大为 2^16 = 64 KB 。
- 如果需要进一步增加接收窗口,可在 TCP Options 中添加 Window scale 参数,占 14 bits 空间。
- 此时用 Window size 与 Window scale 的乘积表示接收窗口的大小,因此接收窗口最大为 2^16 * 2^14 = 1 GB 。
- 每发送一个新的 TCP 包,就可修改本机 Window size 的大小,而 Window scale 的值在 TCP 三次握手时就确定不变了。
- 如果需要进一步增加接收窗口,可在 TCP Options 中添加 Window scale 参数,占 14 bits 空间。
- 增加接收窗口的大小,能提高吞吐量,从而提高数据传输速度,即网速。
- 但网络带宽低、丢包率高时,增加接收窗口的大小,可能加剧网络拥塞,降低网速。
- 接收窗口的大小不应该超过带宽时延积(RDP),否则并不能提高吞吐量。
- RDP 等于
Bandwidth*RTT,表示通信线路中正在传输的最大数据量。 - 例:假设两个主机之间的物理带宽为 100Mbps ,RTT 为 0.2s ,则 RDP 等于 2.5MB 。
- RDP 等于
发送窗口(send window)
- :发送方的发送缓冲区的可用空间,单位 bytes 。
- 通过 TCP 协议发送一批 bytes 数据时,发送方会先将数据暂存到发送缓冲区,然后取出这些数据作为 payload ,封装为 TCP 包并发送。等收到 ACK 确认之后,才删除发送缓冲区中对应的数据,腾出空间。
- 如果发送缓冲区没满,则可以写入新的数据,然后发送。
- 如果发送缓冲区满了,则不能写入新的数据,因此暂停发送。
- 综上,发送窗口决定了发送方最多有多少个数据已发送但未 ACK 确认。
- 发送窗口越大,则允许并行发送的 payload 越多,网速越快。但发送窗口的大小不能超过接收窗口,否则会导致丢包。
- 例:假设发送窗口的初始大小为 300 bytes ,发送方同时发送 Seq number = 0 、Seq number = 100 、Seq number = 200 的 3 个 TCP 包,每个 TCP 包携带 100 bytes 的 payload 。
- 此时发送窗口的大小为 0 ,只能暂停发送新的 payload ,等待 ACK 包。
- 如果发送方收到 Ack number = 100 的 ACK 包,则可以在发送缓冲区写入新的 100 bytes 数据,发送第 4 个 TCP 包。
- 如果发送方收到 Ack number = 300 的 ACK 包,则可以在发送缓冲区写入新的 300 bytes 数据,发送第 4、5、6 个 TCP 包。
滑动窗口(sliding window)
- :接收方将接收窗口的大小告诉发送方,然后发送方据此配置发送窗口的大小,一般让发送窗口小于、接近接收窗口。
- 优点:通过滑动窗口这个机制,可控制并行流量的大小、数据传输速度。
操作系统会自动完成滑动窗口等任务。例:假设两个 Linux 主机上的程序之间进行 TCP 通信,程序 A 调用 send() 发送数据,程序 B 调用 recv() 接收数据。
- 如果程序 B 调用 recv() 处理数据的速度较慢,导致一些 bytes 数据堆积在接收缓冲区中尚未处理,则程序 B 的操作系统会自动减小在 ACK 包中声明的 Window size ,从而通知发送方减小发送窗口。
- 极端情况下,接收缓冲区满了,此时接收窗口为 0 ,使得发送窗口也为 0 ,称为窗口关闭。
- 窗口关闭之后,发送方会每隔一定时长,发送一个用于 window probe 的 TCP 包,询问接收方当前接收窗口的大小。如果非 0 ,则发送方可以继续发送数据。
- 如果接收窗口的大小只有几 bytes ,使得发送窗口也只有几 bytes ,此时 payload 比 TCP header 小得多,传输数据的效率很低,加剧了网络拥塞,称为糊涂窗口综合征(Silly Window Syndrome)。解决方案如下:
- 接收方通常在接收窗口小于 MSS 时,或者小于接收缓冲区的一半时,就直接关闭接收窗口。
- 发送方通常启用 Nagle 算法,在满足以下任一条件时才发送 TCP 包:
- 如果已发送的 TCP 包都 ACK 确认,则立即发送新的 TCP 包,使得发送方至少有一个 TCP 包已发送但未 ACK 确认。
- 如果发送缓冲区堆积的数据超过 MSS ,则立即发送新的 TCP 包。
- 有的程序不采用 Nagle 算法,比如 SSH 。因为比起传输数据的效率,它们更追求低延迟、实时性,即使发送缓冲区只有几 bytes 数据,也会立即发送。
- 在 Linux 上,通过 Socket 发送 TCP 数据时默认启用 Nagle 算法,配置 TCP_NODELAY 会禁用 Nagle 算法。
# 拥塞控制
什么是拥塞控制?
- 现代计算机的通信线路挺可靠,几乎不会因为信道质量问题而丢包,除非是 WiFi 这种容易受干扰的通信。
- 当用户感觉电脑网速变慢时,通常是因为信道中当前传输的数据量太多,占满了物理带宽(比如一栋公寓里可能多个用户共用一条线路),该问题称为网络拥塞(Network Congestion)。
- 网络拥塞会导致通信延迟、丢包率增加,触发超时重传,但重传的 TCP 包又会加剧网络拥塞,导致恶性循环。因此计算机在发现网络拥塞时,应该自动减少发送的数据量,该操作称为拥塞控制。
如何做拥塞控制?
- 为了减少网络拥塞,发送方通常采用一些拥塞控制算法(Congestion Control Algorithm),控制自己发送 TCP 包的过程。
- 拥塞控制算法通常只影响发送方,不影响接收方。
- TCP 通信双方会轮流担任发送方,因此可分别采用不同的拥塞控制算法。
- 即使同一个发送方,也可以随时使用不同的拥塞控制算法。
TCP Tahoe
- :1988 年,加州大学伯克利分校的 Van Jacobson 在论文 Congestion Avoidance and Control (opens new window) 中设计了一套拥塞控制方案,发明了拥塞窗口、慢启动、快速重传等算法。
- 这些算法被应用在 BSD 操作系统中,当时的 BSD 版本号为 Tahoe ,因此统称为 TCP Tahoe 算法。之后发明的拥塞控制算法,大多借鉴了 TCP Tahoe 算法。
- 基本原理:发送方每隔 RTT 时间,就增加自己的并发通信量。如果发现网络拥塞,则立即降低自己的并发通信量。
- 拥塞窗口(Congestion Window,cwnd)
- :发送方会计算一个变量 cwnd ,称为拥塞窗口。然后将当前接收窗口(rwnd)、拥塞窗口(cwnd)中较小的一个值,配置为发送窗口(swnd)的大小。
- 在接收窗口足够使用的情况下,发送方通过调整拥塞窗口的大小,就能调整自己的并发通信量。
- cwnd 取值通常为 n 倍 MSS 。
- 慢启动(Slow Start)
- :刚建立 TCP 连接时,发送方不知道网络拥塞程度。出于保守预测,配置一个较小的 cwnd 初始值。之后每次发送 n bytes 的 payload 并收到 ACK 确认,就将 cwnd 增加 n bytes ,即每隔 1 RTT 时间就将 cwnd 翻倍,因此网速会呈指数增长。
- 例如 Linux 为每个 Socket 配置的 cwnd 初始值为 10 倍 MSS 。则慢启动流程如下:
- 第一个 RTT 时间内:发送方发出
10*MSSbytes 的数据,封装为 10 个 TCP 包。如果顺利收到 ACK 确认,则将 cwnd 增加10*MSS。 - 第二个 RTT 时间内:发送方发出
20*MSSbytes 的数据,封装为 20 个 TCP 包。如果顺利收到 ACK 确认,则将 cwnd 增加20*MSS。 - 第三个 RTT 时间内:发送方发出
40*MSSbytes 的数据,封装为 40 个 TCP 包。如果顺利收到 ACK 确认,则将 cwnd 增加40*MSS。 - 第四个 RTT 时间内:发送方发出
80*MSSbytes 的数据,封装为 80 个 TCP 包。如果顺利收到 ACK 确认,则将 cwnd 增加80*MSS。
- 第一个 RTT 时间内:发送方发出
- 优点:
- 新建的 TCP 连接不会突然爆发大量流量,对网络造成冲击。
- 缺点:
- 每次建立新的 TCP 连接时,需要经过慢启动,网速才会增长到正常水平。RTT 越大,启动越慢。
- 拥塞避免(Congestion Avoidance)
- :开始慢启动后,当 cwnd 较大时,发送方担心发生网络拥塞。出于保守预测,每次发送 cwnd bytes 的 payload 并收到 ACK 确认,只将 cwnd 增加 1 倍 MSS ,即每隔 1 RTT 时间只增加 1 倍 MSS ,因此网速变成线性增长。
- 发送方会计算一个变量 ssthresh ,称为慢启动阈值,用于衡量 cwnd 是否较大。
- 当 cwnd < ssthresh 时,认为发生网络拥塞的概率低,因此采用慢启动算法。
- 当 cwnd ≥ ssthresh 时,认为发生网络拥塞的概率高,因此采用拥塞避免算法。
- ssthresh 初始值通常很大,等发生网络拥塞,才将 ssthresh 改为之前 cwnd 的一半。
- 上述的慢启动算法、拥塞避免算法都是用于降低网络拥塞概率,但如果真的发生网络拥塞怎么办?TCP Tahoe 采用以下对策:
- 如果 RTO 定时器超时,则触发超时重传。如果收到 3 个重复的 ACK 包,则触发快速重传。这两种情况下,都认为发生了网络拥塞。
- 如果发生超时重传或快速重传,则将 ssthresh 改为之前 cwnd 的一半,将 cwnd 改为初始值,重新慢启动。
- 该过程与拥塞避免组合在一起,就构成了控制 cwnd 的加法增大/乘法减小(Additive-Increase / Multiplicative-Decrease,AIMD)算法。
- 缺点:每次网络拥塞,就将 cwnd 下降到初始值,可能导致网速突降 99% ,太保守了,鲁棒性差。
- :1988 年,加州大学伯克利分校的 Van Jacobson 在论文 Congestion Avoidance and Control (opens new window) 中设计了一套拥塞控制方案,发明了拥塞窗口、慢启动、快速重传等算法。
TCP Reno
- :1990 年,BSD 操作系统发布了名为 Reno 的版本,对 TCP Tahoe 算法做了改进,称为 TCP Reno 算法。
- 2009 年,TCP 拥塞控制的规范 RFC 5681 (opens new window) 发布,大体与 TCP Reno 相似,包含四个常用的拥塞控制算法:慢启动、拥塞避免、快速重传、快速恢复,又称为四个阶段。
- 特点:
- 如果发生超时重传,则认为大概率发生了网络拥塞,像 TCP Tahoe 一样处理。
- 如果发生快速重传,则认为小概率发生了网络拥塞,毕竟还能重复收到 3 个 Ack number = N 包,而不是一个 ACK 包都没收到,因此执行快速恢复算法。
- 快速恢复(Fast Recovery)是快速重传的改进版,流程如下:
- 将 ssthresh 改为之前 cwnd 的一半,将 cwnd 改为
sshthresh + 3*MSS,其中3*MSS表示已收到 3 个 ACK 包。 - 快速重传 Seq number = N 的包。
- 如果依然重复收到 Ack number = N 包,则每收到一个,就将 cwnd 增加 1 倍 MSS 。
- 如果收到 Ack number > N 的新包,则结束快速恢复算法。然后将 cwnd 改为 sshthresh 的值,跳过慢启动阶段,直接进入拥塞避免阶段。
- 将 ssthresh 改为之前 cwnd 的一半,将 cwnd 改为
- 优点:
- 每次网络拥塞,大概将 ssthresh、cwnd 减半,比 TCP Tahoe 的降幅小。
- TCP Reno 等传统拥塞控制算法判断网络拥塞的依据为是否超时重传、快速重传,即是否丢包。因此存在以下缺点:
- 每次网络拥塞,就大幅降低 cwnd ,导致网速剧烈波动(甚至周期性一会大、一会小),造成的网络负载也剧烈波动,鲁棒性差。
- 总是假设网络的丢包率为 0% ,因此一旦丢包,就认为发生了网络拥塞。但有的网络可能经常丢包(比如无线网络),如果每次 ACK 包丢失都降低 cwnd ,则会导致网速一直低。
- 发生网络拥塞时,发送方会无私地降低自己的 cwnd ,因此不容易造成网络拥塞的恶性循环。但与其它主机共用一个网络信道时,可能被恶意抢占带宽。
- 为了减少丢包率,一些通信设备制造商给路由器、交换机配置了较大容量的缓冲区,用于暂存来不及传输的数据包,延后传输它们。但这样会导致传统拥塞控制算法失灵:
- 如果缓冲区不为空,则所有数据包都要在缓冲区中排队传输,增加了传输延迟。
- 如果缓冲区不为空,则说明网络已经拥塞,但传统拥塞控制算法还不能发现这个事实,直到缓冲区满了、开始丢包,才降低 cwnd 。在此期间,越来越多的数据包暂存到缓冲区,进一步增加了传输延迟、网络负载,该问题称为缓冲区膨胀(Bufferbloat)。
- :1990 年,BSD 操作系统发布了名为 Reno 的版本,对 TCP Tahoe 算法做了改进,称为 TCP Reno 算法。
TCP New Reno
- :1995 年发布的一个拥塞控制算法,改进了 TCP Reno 中的快速恢复算法。
- 如果在同一个滑动窗口内,有多个 TCP 包传输失败:
- TCP Reno 会多次触发快速恢复,多次将 ssthresh、cwnd 减半。
- TCP New Reno 只会触发一次快速恢复,逐个找出缺少的 TCP 包并重传,因此只将 ssthresh 减半一次。例如:
- 发送方已发送的最新 Seq number 为 400 ,却重复收到 3 个 Ack number = 100 的包,则快速重传 Seq number = 100 的包。
- 重传之后收到新的 Ack 包,如果此时的 Ack number 依然小于 400 ,则从该 Ack number 处继续重传。
- 两个算法都假设未启用 SACK 功能,从而提高通用性。
- 优点:丢包率越高,TCP New Reno 的性能比 TCP Reno 越好。
TCP BIC
- 通过二分法寻找 cwnd 可用的最大值。
- Linux kernel 2.6.8 开始,采用它作为默认的拥塞控制算法。
TCP CUBIC
- 是 BIC 的改进版本,通过三次函数寻找 cwnd 可用的最大值。
- Linux kernel 2.6.19 开始,采用它作为默认的拥塞控制算法。执行命令
sysctl net.ipv4.tcp_congestion_control即可查看。 - 目前互联网最常用的拥塞控制算法是 CUBIC ,但未来可能被 BBR 取代。
TCP BBR(Bottleneck Bandwidth and Round-trip propagation time)
- :2016 年,Google 公司发布的一个拥塞控制算法。
- 传统拥塞控制算法判断网络拥塞的依据为丢包。而 BBR 算法会监控最近一段时间的 RTT ,寻找 cwnd 可用的最大值。因此:
- BBR 能容忍网络存在一定的丢包率。
- 一旦发生缓冲区膨胀,BBR 能根据 RTT 的增长及时发现网络拥塞,降低 cwnd 。
- 优点:
- 在 RTT 超过 100ms 且丢包率超过 1% 的情况下,比传统拥塞控制算法的吞吐量高几百倍、通信延迟低 10% 。
- 鲁棒性好,发生网络拥塞时不会大幅降低 cwnd 。
- Linux kernel 4.9 加入了 BBR 算法,但默认禁用。
综上,存在多种拥塞控制算法。在不同的使用场景下,可能选用不同的拥塞控制算法。为了比较它们的优劣,通常计算以下性能指标:
- 吞吐量(throughput)
- 延迟(delay)
- 丢包率(packet loss rate)
- 公平性(fairness):多个主机共用一个网络信道时,能否公平地分配带宽,提高整个网络的带宽利用率。
- 收敛时间(convergence times):新建的 TCP 连接,需要多久才能让 cwnd 趋于稳定值。
- 鲁棒性(robustness):发生网络拥塞时,能否快速让 cwnd 恢复到稳定值。