# Alertmanager
:一个 Web 服务器,用于将 Prometheus 产生的警报加工之后转发给用户。
- GitHub (opens new window)
- 优点:
- Prometheus 产生的警报是 JSON 格式的信息,Alertmanager 可以对它们进行分组管理,加工成某种格式的告警消息,再转发给用户。
- 配置比较麻烦但是很灵活。
- 可以在 Web 页面上搜索警报、分组管理。
- 缺点:
- 只能查看当前存在的警报,不能查看已发送的历史消息。
# 原理
# 工作流程
- Prometheus 每隔 interval 时长执行一次 alert rule 。如果执行结果包含 n 个时间序列,则认为存在 n 个警报,通过 HTTP 通信发送 alerting 状态的消息给 Alertmanager 。
- Alertmanager 收到之后,
- 先根据 route 判断它属于哪个 group 、应该发送给哪个 receiver 。
- 再判断该 group 当前是否处于冷却阶段、是否被 Silence 静音、是否被 Inhibit 抑制。如果都没有,则立即发送告警消息给用户。
- 如果 Prometheus 再次执行 alert rule 时,发现执行结果为空,则认为警报已解决,立即产生 resolved 状态的消息,发送给 Alertmanager 。
- Alertmanager 收到之后,立即发送给用户。
- 如果一个指标不再满足告警条件,或者 Prometheus 不再抓取相应的指标,或者不再执行相应的 alert rule ,都会让 Prometheus 认为该警报已解决,产生一个 resolved 状态的消息,发送给 Alertmanager 。
- 目前在 Prometheus 端并不能控制是否产生 resolved 消息,只能在 Alertmanager 端控制是否发送 resolved 消息。
# 主要概念
- Filter
- :通过 label=value 的形式筛选警报。
- 它方便在 Web 页面上进行查询。
- Group
- :根据 label 的值对警报进行分组。
- 它需要在配置文件中定义,但也可以在 Web 页面上临时创建。
- Silence
- :不发送某个或某些警报,相当于静音。
- 它需要在 Web 页面上配置,且重启 Alertmanager 之后不会丢失。
- Inhibit
- :用于设置多个警报之间的抑制关系。当发出某个警报时,使其它的某些警报静音。
- 它需要在配置文件中定义。
- 被静音、抑制的警报不会在 Alertmanager 的 Alerts 页面显示。
# 部署
下载后启动:
./alertmanager --config.file=alertmanager.yml # --web.config.file=web.yml # --web.listen-address "0.0.0.0:9093" # 监听的地址 # --web.external-url "http://10.0.0.1:9093/" # 供外部访问的 URL # --cluster.listen-address "0.0.0.0:9094" # 集群监听的地址(默认开启) # --data.retention 120h # 将数据保存多久 --log.format=json或者用 docker-compose 部署:
version: "3" services: alertmanager: container_name: alertmanager image: prom/alertmanager:v0.28.1 restart: unless-stopped command: - --config.file=alertmanager.yml - --web.config.file=web.yml ports: - 9093:9093 volumes: - .:/alertmanager需要调整挂载目录的权限:
mkdir data chown -R 65534 .
# 配置
使用 Alertmanager 时,需要在 Prometheus 的配置文件中加入如下配置,让 Prometheus 将警报转发给它处理。
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.0.0.1:9093
alertmanager.yml 的配置示例:
global: # 配置一些全局参数
# resolve_timeout: 5m # 如果 Alertmanager 收到的警报 JSON 中不包含 EndsAt ,则超过该时间之后就认为该警报已解决
smtp_smarthost: smtp.exmail.qq.com:465
smtp_from: [email protected]
smtp_auth_username: [email protected]
smtp_auth_password: ******
smtp_require_tls: false
# templates: # 从文件中导入告警消息模板
# - templates/*
receivers: # 定义告警消息的接受者
- name: email_to_leo
email_configs: # 只配置少量 smtp 参数,其余的参数则继承全局配置
- to: [email protected] # 收件人,如果有多个邮箱地址则用逗号分隔
# send_resolved: false # 是否在警报消失时发送 resolved 状态的消息
# html: '{{ template "email.default.html" . }}' # 设置 HTML 格式的邮件 body
# headers:
# subject: '[{{.GroupLabels.severity}}] {{.GroupLabels.alertname}}' # 设置邮件标题
# - to: [email protected] # 可以指定多个发送地址
- name: webhook_to_leo
webhook_configs:
- url: http://localhost:80/
route:
receiver: email_to_leo
# inhibit_rules: # 设置一些警报之间的抑制关系
# - ...
# mute_time_intervals: # 在某些时间段关闭告警
# - ...
# templates
告警消息模板的示例:
{{ define "custom_email" }} # 定义一个模板,指定名称
<!DOCTYPE html>
<html>
<body>
<b>目前有 {{ .Alerts | len }} 个警报,其中 {{ .Alerts.Firing | len }} 个为 firing 状态,{{ .Alerts.Resolved | len }} 个为 Resolved 状态。警报列表如下:</b>
{{ range .Alerts.Firing }} # 遍历每个 Firing 状态的警报
<hr style="opacity: 0.5;"/>
StartsAt : {{ .StartsAt }}<br />
instance : {{ .Labels.instance }}<br />
{{ range .Annotations.SortedPairs }}
{{ .Name }} : {{ .Value }}<br />
{{ end }}
{{ end }}
</body>
</html>
{{ end }} # 模板定义结束
# route
route 块定义了分组处理警报的规则,如下:
route:
receiver: email_to_leo # 只能指定一个接收方
group_wait: 2m
group_interval: 5m
repeat_interval: 24h
group_by: # 根据标签的值对已匹配的警报进行分组(默认不会分组)
- alertname
routes:
- receiver: webhook_to_leo
# group_by:
# - alertname
matchers: # 筛选出目标警报,需要其 labels 同时匹配以下 PromQL 条件,如果 matchers 列表为空则选出所有警报。不支持匹配 annotations
- job = prometheus # 可选在运算符左右加空格
- instance =~ 10.0.0.* # 可选加上字符串定界符
- '{alertname !~ "进程停止"}' # 可选加上字符串定界符、花括号 {}
# continue: false
- receiver: xxx
...
- 上例中的大部分参数都不是必填项,最简单的 route 块如下:
route: receiver: email_to_leo - 配置文件中必须要定义 route 块,其中至少要定义一个 route 节点,称为根节点。
- 在根节点之下可以定义任意个嵌套的 route 块,构成一个树形结构的路由表。
- 子节点会继承父节点的所有参数值,作为自己的默认值。
- Alertmanager 每收到一个警报时,会从根节点往下逐个尝试匹配。
- 如果当前节点匹配:
- 如果子节点不匹配,则交给当前节点处理。
- 如果子节点也匹配,则交给子节点处理。(相当于子节点覆盖了父节点)
- 如果配置了
continue: true,则还会继续尝试匹配之后的同级节点。否则结束匹配,退出路由表。
- 如果当前节点不匹配,则会继续尝试匹配之后的同级节点。
- 警报默认匹配根节点。因此,如果所有节点都不匹配,则会交给根节点处理。
- 如果当前节点匹配:
- Alertmanager 以 group 为单位发送告警消息。
- 每次发送一个 group 的消息时,总是会将该 group 内现有的所有警报合并成一个告警消息,一起发送。
- 当一个 group 中出现第一个警报时,会先等待
group_wait时长再发送该 group 。- 延长 group_wait 时间有利于收集属于同一 group 的其它警报,一起发送。
- 当一个 group 的警报一直存在时,要至少冷却
repeat_interval时长才能重复发送该 group 。- 实际上,是要求当前时刻与上一次发送时刻的差值大于 repeat_interval 。 因此,即使重启 Alertmanager ,也不会影响 repeat_interval 的计时。 不过,在配置文件中修改 group_wait、repeat_interval 等参数的值时,会立即生效。
- 当一个 group 处于冷却阶段时:
- 如果收到一个属于该 group 的新警报,则会等待
group_interval时长之后让该 group 解除冷却,发送一次消息,并且从当前时刻开始重新计算 repeat_interval 。 - 如果一个警报被解决了,也会让该 group 解除冷却,发送一次 resolved 消息。
- 如果一个被解决的警报再次出现,也会让该 group 解除冷却,发送一次消息。
- 因此,如果一个警报反复被解决又再次出现,则会绕过 repeat_interval 的限制,导致 Alertmanager 频繁发送消息给用户。
- 如果收到一个属于该 group 的新警报,则会等待
特殊情况:
- 假设 Prometheus 与 Alertmanager 正常连接,且存在一些警报:
- 如果两者断开连接,则大概两分钟之后 Alertmanager 会自行认为所有警报已解决,发送 resolved 状态的消息给用户。
- 如果两者重新连接,则 Alertmanager 会认为这些警报的 group 是新出现的,立即发送 alerting 状态的消息给用户。
- 因此,如果两者反复断开连接又重新连接,则会绕过 repeat_interval 的限制,导致 Alertmanager 频繁发送消息给用户。
- 假设一个新警报出现,Alertmanager 正常地发送一次告警消息给用户。
- 如果此时用 Silence 隐藏该警报,则 Alertmanager 的首页上不会显示该警报,但并不会发送 resolved 消息给用户。
- 如果接着在 Prometheus 端解决该警报,则 Alertmanager 也不会发送 resolved 消息。
- 如果接着取消 Silence ,则 Alertmanager 依然不会发送 resolved 消息。
# inhibit_rules
例:
inhibit_rules:
- source_matchers:
- severity = error
target_matchers:
- severity = warn
equal:
- alertname
- instance
- source_matchers:
- alertname = target 离线
- job = node_exporter
target_matchers:
equal:
- nodename
- 工作原理: Alertmanager 会先根据 source_matchers 指定的 label:value 选中一些警报,再根据 target_matchers 选中一些警报。如果 source 警报存在,则抑制与它 equal 标签值相同的 target 警报。
- 如果 equal 列表为空,或者 source 警报与 target 警报都不具有 equal 标签(此时相当于它们的该标签值都为空),则抑制所有 target 警报。
- 如果 target 警报与 source 警报相同,并不会抑制 source 警报本身。
- 上例中,第一条抑制规则的作用是:当出现 severity 为 error 的警报时,抑制与它同类型、但 severity 为 warn 的其它警报。
- 上例中,第二条抑制规则的作用是:当某个主机离线时,抑制该主机的其它警报。
# 用法
Prometheus 的 Alerts 页面示例:
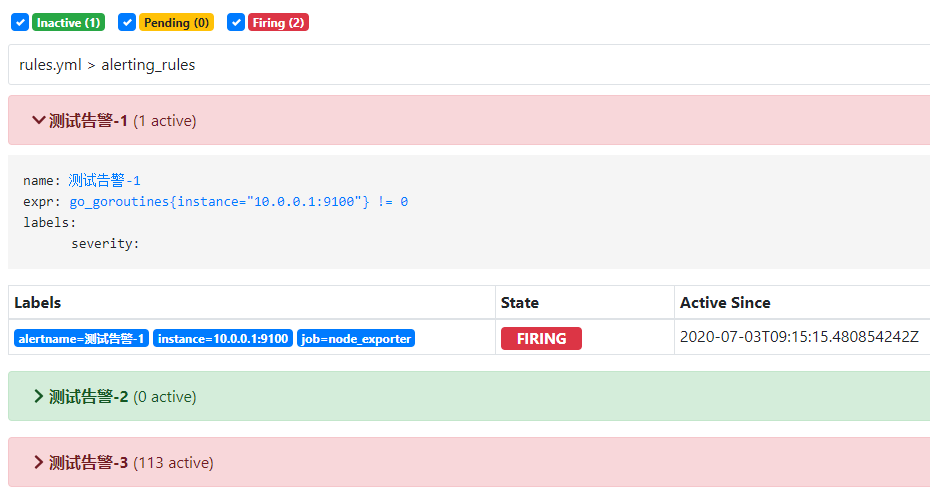
- 上图中,处于 Inactive、Pending、Firing 状态的 alerting_rule 分别总共有 1、0、2 个。
- rules.yml 文件中定义了三条 alerting_rule 。
- 第一条 alerting_rule 名为 “测试告警-1” ,包含 1 个 active 的警报。
- 每个警报源自一个满足 alerting_rule 的时间序列。
- Active Since 表示警报从什么时候开始存在,即进入 pending 状态的时刻。如果警报中断,则会刷新该时刻。
- 第三条 alerting_rule 名为 “测试告警-3” ,包含 113 个 active 状态的警报。
- 第一条 alerting_rule 名为 “测试告警-1” ,包含 1 个 active 的警报。
Alertmanager 的 Alerts 页面示例:
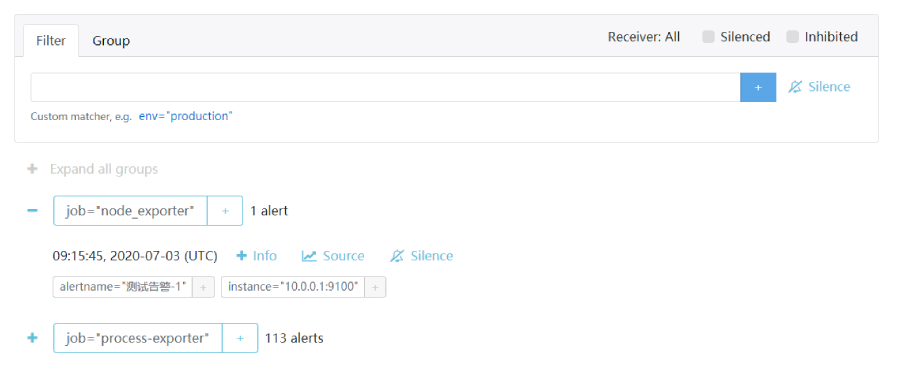
- 上图中存在两个 group :
- 第一个 group 是 job="node_exporter" ,包含 1 个警报。
- 第二个 group 是 job="process-exporter" ,包含 113 个警报。
- 上图中存在一个 instance="10.0.0.1:9100" 的警报:
- 09:15:45 UTC 表示该警报的产生时刻,即在 Prometheus 那边变成 Firing 状态的时刻。重启 Alertmanager 也不会影响该时刻。
- 点击 Info 会显示该警报的详细信息。
- 点击 Source 会跳转到 Prometheus ,查询该警报对应的指标数据。
- 点击 Silence 可以静音该警报。
# HTTP API
GET /-/healthy # 用于健康检查,总是返回 Code 200
GET /-/ready # 返回 Code 200 则代表可以处理 HTTP 请求
POST /-/reload # 重新加载配置文件